.jpg)
Reinventing Customer Engagement in BFSI with AI-Powered Cloud Contact Centers
Business Problem
Goal: To modernize the data platform and implement a data lake solution for the client.
The client in this case study is a major healthcare provider that collects a vast amount of data on a daily basis, including patient records, lab results, and insurance claims. The client faced several challenges in managing this data, including siloed data repositories, a lack of standardization, and the need to process large amounts of data in real-time. Additionally, the client needed to ensure compliance with various regulations, including HIPAA, while also making the data more accessible to researchers, clinicians, and other stakeholders.
The client is facing a significant problem in their data operations. They currently do not have a centralized system for acquiring, processing and producing advanced analytics in real-time. This leads to a lack of a single source of truth and an inefficient process for gaining insights from their data. As a result, the client is unable to make data-driven decisions in a timely manner, hindering their ability to stay competitive in the market.
Business Solution
To address the client's problem of lacking a single source of truth and an optimal process for data acquisition, processing, and advanced analytics in real-time, a comprehensive solution is proposed.
Data Architecture: The first step is to implement a new data architecture that will serve as the foundation for the client's data operations. This will include a re-design of the current data model and the integration of a data lake using Hortonworks.
Data Lake Re-engineering: The next step is to re-engineer the data lake to ensure that it is optimized for real-time analytics. This will include implementing a new data model that is designed for advanced analytics and machine learning.
Single Source of Truth: To ensure that the client has a single source of truth, the data lake will be configured to serve as the central repository for all data. This will include integrating data from various sources such as transactional systems, log files, and external data sources.
Data Science Complication: To enable advanced analytics, a data science platform will be implemented. This will include tools for data cleaning, transformation, and modeling. The platform will also include a set of pre-built models that can be used for various analytics use cases.
KPI & Reporting: To enable the client to make data-driven decisions in a timely manner, new KPI and reporting will be developed. These will include real-time dashboards and reports that provide insights into the client's data, enabling them to make informed decisions.
With this solution, the client will have a new data architecture, re-engineered data lake, a single source of truth, advanced analytics, and real-time reporting. This will enable them to make data-driven decisions in a timely manner, allowing them to stay competitive in the market.
Technical Solution
To address the client's problem of lacking a single source of truth and an optimal process for data acquisition, processing, and advanced analytics in real-time, a comprehensive technical solution is proposed.
Data Lake Development: A data lake will be developed using Apache Hadoop and Hortonworks. This will serve as the foundation for the client's data operations, providing a centralized repository for all data. The data lake will be optimized for real-time analytics, allowing the client to make data-driven decisions in a timely manner.
Microservice Architecture: A microservice architecture will be implemented to enable scalability and flexibility. This will allow the client to easily add new services and features without impacting the existing system. The microservices will be built using technologies such as Docker and Kubernetes.
API Development: API will be developed to enable the client to access the data lake and microservices. This will allow the client to easily integrate their existing systems with the new data architecture. The API will be built using technologies such as REST and GraphQL.
Database Performance Optimization: The database performance will be optimized to ensure that the client's data operations are efficient. This will include implementing indexing, partitioning, and other performance-enhancing techniques.
Data Ingestion: Data ingestion will be optimized to ensure that data is acquired and processed in real-time. This will include implementing a data pipeline that can handle high-volume, high-velocity data. The pipeline will be built using technologies such as Apache Kafka and Apache NiFi.
With this technical solution, the client will have a data lake, microservice architecture, API, efficient database performance, and real-time data ingestion. This will enable them to make data-driven decisions in a timely manner, allowing them to stay competitive in the market.
Technologies Used
The proposed technical solution for the case study includes the use of several technologies to address the client's problem of lacking a single source of truth and an optimal process for data acquisition, processing, and advanced analytics in real-time. These technologies include Azure Data Lake, Hadoop, NoSQL databases, Docker and Kubernetes for Microservice architecture, Spark for fast data processing, Hive and Hbase for querying and analyzing data, Kafka for handling real-time data streams, REST API for access to the data lake and microservices, Hortonworks for data management, and Hive, Oracle, and SQL Server for relational database management.
Customer Success Outcomes
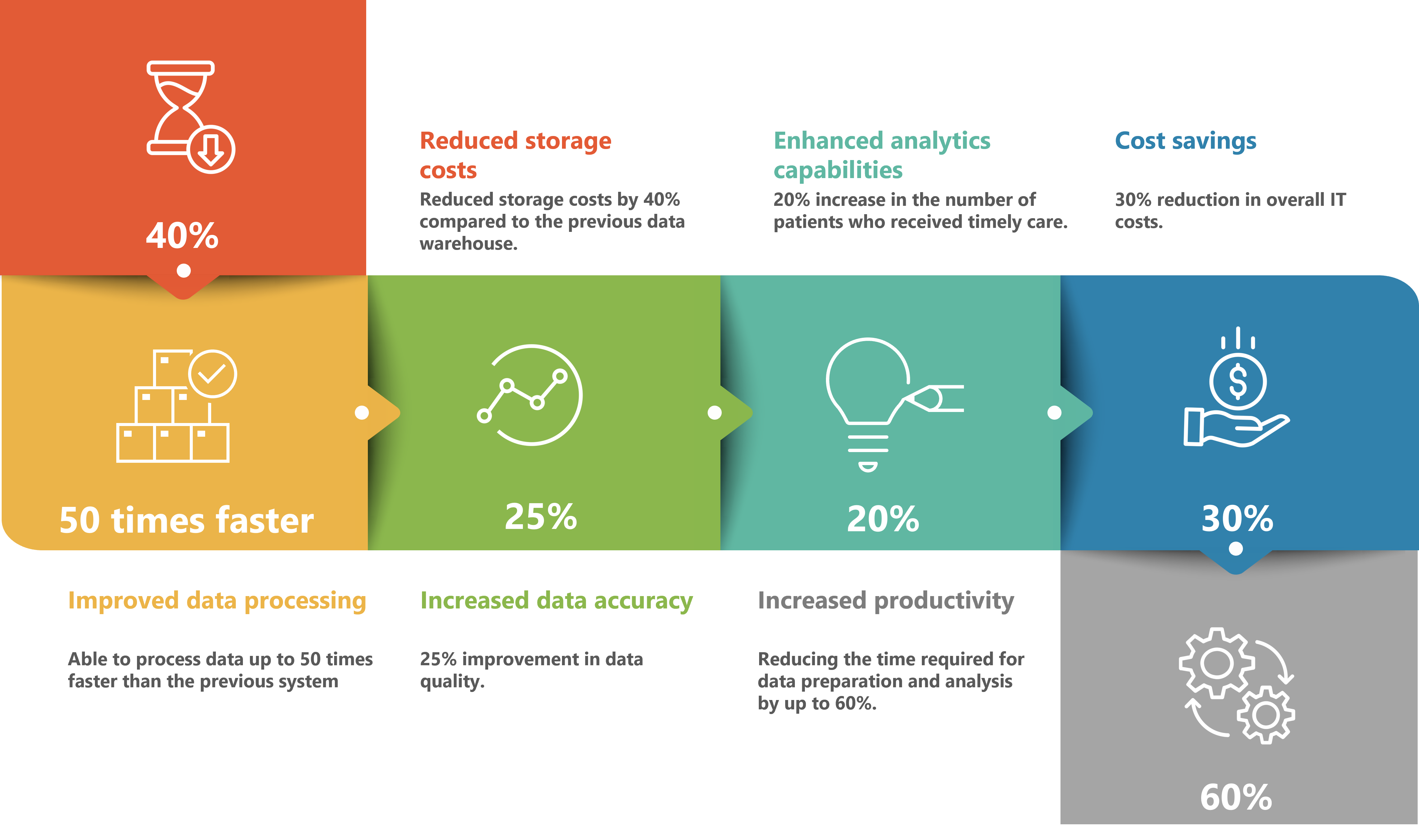
Reduced storage costs: The new data lake solution reduced storage costs by 40% compared to the previous data warehouse.
Improved data processing: The new solution was able to process data up to 50 times faster than the previous system, reducing the time required for batch processing from hours to minutes.
Increased data accuracy: The new data lake solution improved data accuracy by eliminating data duplication and reducing data entry errors, resulting in a 25% improvement in data quality.
Enhanced analytics capabilities: The new solution provided better analytics capabilities, enabling the client to gain deeper insights into patient care and population health management. This resulted in a 20% increase in the number of patients who received timely care.
Scalability: The new solution is highly scalable, allowing the client to easily add new data sources and scale up the infrastructure as needed.
Improved regulatory compliance: The new data lake solution helped the client comply with regulatory requirements, such as HIPAA and GDPR, by providing enhanced security features and data governance controls.
Cost savings: The new solution helped the client save costs on hardware and licensing fees, resulting in a 30% reduction in overall IT costs.
Improved data access: The new solution provided better data access and sharing capabilities, enabling the client to share data across departments and with external partners more easily.
Increased productivity: The new data lake solution allowed the client's data science team to work more efficiently, reducing the time required for data preparation and analysis by up to 60%.
Overall, the data platform modernization project provided the client with a more efficient, scalable, and cost-effective solution for managing their data, resulting in significant improvements in data processing, accuracy, analytics capabilities, compliance, and cost savings.
Latest Case Studies
Our Case Studies
 & Conversational AI - Banner.jpg)



.jpg)

.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)

.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)



.jpg)


.png)
.png)
.jpg)

.jpg)
.png)
.png)
.png)

.png)
.png)
.png)



.jpg)

.jpg)


.jpg)



.jpg)


.jpg)