.jpg)
Reinventing Customer Engagement in BFSI with AI-Powered Cloud Contact Centers
Business Problem
Major Financial Services Company, like many other financial institutions, is subject to the annual Comprehensive Capital Analysis and Review (CCAR) conducted by the Federal Reserve. The CCAR is designed to ensure that institutions have well-defined and forward-looking capital planning processes that account for their unique risks and sufficient capital to continue operations through times of economic and financial stress.
One of the critical components of the CCAR is the ability to demonstrate the Data Lineage for all the Critical Data elements. Data Lineage refers to the ability to trace the origin and movement of data through the various stages of its lifecycle, including its creation, modification, and deletion. This information is essential for understanding the accuracy and completeness of the data used in the CCAR process.
However, Financial Services Company is facing a challenge in building Data Lineage for all the Critical Data elements. The company's data is scattered across multiple systems and platforms, making it difficult to trace the origin and movement of the data. Additionally, the company lacks an automated process for tracking and documenting data lineage, which is time-consuming and prone to errors.
To address these challenges, Financial Services Company needs to implement a comprehensive solution that can automate the process of tracking and documenting data lineage for all the Critical Data elements. This solution should be able to integrate with multiple systems and platforms and provide a clear and accurate view of the data's origin and movement. By implementing such a solution, the company will be able to demonstrate the Data Lineage for all the Critical Data elements and ensure compliance with the CCAR requirements.
Business Solution
To address the challenge of building Data Lineage for all the Critical Data elements, financial services company decided to implement a comprehensive solution that can automate the process of tracking and documenting data lineage. This solution will integrate with multiple systems and platforms across the organization and provide a clear and accurate view of the data's origin and movement.
The solution will be built on a data integration platform that will extract, transform and load the data from various systems and platforms into a centralized data lake. A metadata management tool will be used to capture the data lineage information, such as data source, transformation logic and target system. This will provide a complete view of the data's journey from its origin to its final destination.
To facilitate the access of Data Lineage information for business users, a self-service data catalog will be built on top of the data lake. This data catalog will enable business users to search, browse and understand the data lineage information easily. It will also provide an intuitive interface for business users to access the data lineage information without the need for technical expertise.
In addition, the solution will also include data governance and security features to ensure that the data lineage information is accurate and protected. This will include access controls, data encryption and masking, and monitoring and auditing capabilities.
By implementing this solution, financial services company will be able to automate the process of tracking and documenting data lineage for all the Critical Data elements. This will ensure compliance with the CCAR requirements, and provide business users with easy access to data lineage information, helping them make better-informed decisions.
Technical Solution
To address the challenge of building Data Lineage for all the Critical Data elements, financial services company decided to implement a technical solution that utilizes the Erwin tool.
The first step in the solution was to analyze all the critical data elements provided by the business team and develop the Metadata mapping. This included identifying the source systems and platforms, the transformation logic, and the target systems for each data element.
Next, the Erwin tool was configured to capture the data lineage information on all the layers of the entities that constitute the critical data elements, from the source to the final publish layer. This provided a clear and accurate view of the data's origin and movement.
To ensure that the data lineage information was complete, the solution was built to cover all the data elements that are required for the business, specifically the Critical Data Elements (CDEs). This included capturing the data lineage information for data elements such as financial transactions, customer information, and regulatory reporting.
Finally, the data lineage information was published to the business team using Erwin's WEB-PORTAL. This provided a self-service access for the business team to search, browse, and understand the data lineage information easily. The WEB-PORTAL also provided an intuitive interface for business users to access the data lineage information without the need for technical expertise.
By implementing this technical solution, financial services company was able to automate the process of tracking and documenting data lineage for all the Critical Data elements. This ensured compliance with the CCAR requirements and provided business users with easy access to data lineage information, helping them make better-informed decisions.
Technologies
In this case study, a variety of technologies were used to implement a big data solution. Hadoop and Spark were utilized for distributed storage and processing of large amounts of data. Scala was the programming language used to write the code for the application. Cloudera was the distribution of Hadoop used, providing a complete big data platform. Informatica was used for data integration and Microservices architecture was used to build the application. Python was used for data processing and Tensorflow was used for machine learning tasks. ERWIN Data Modeler was used for data modeling and ErWin Web-Portal was used to access the data model. Atlassian FishEye and Crucible were used for code review and collaboration.
Customer Success Outcomes
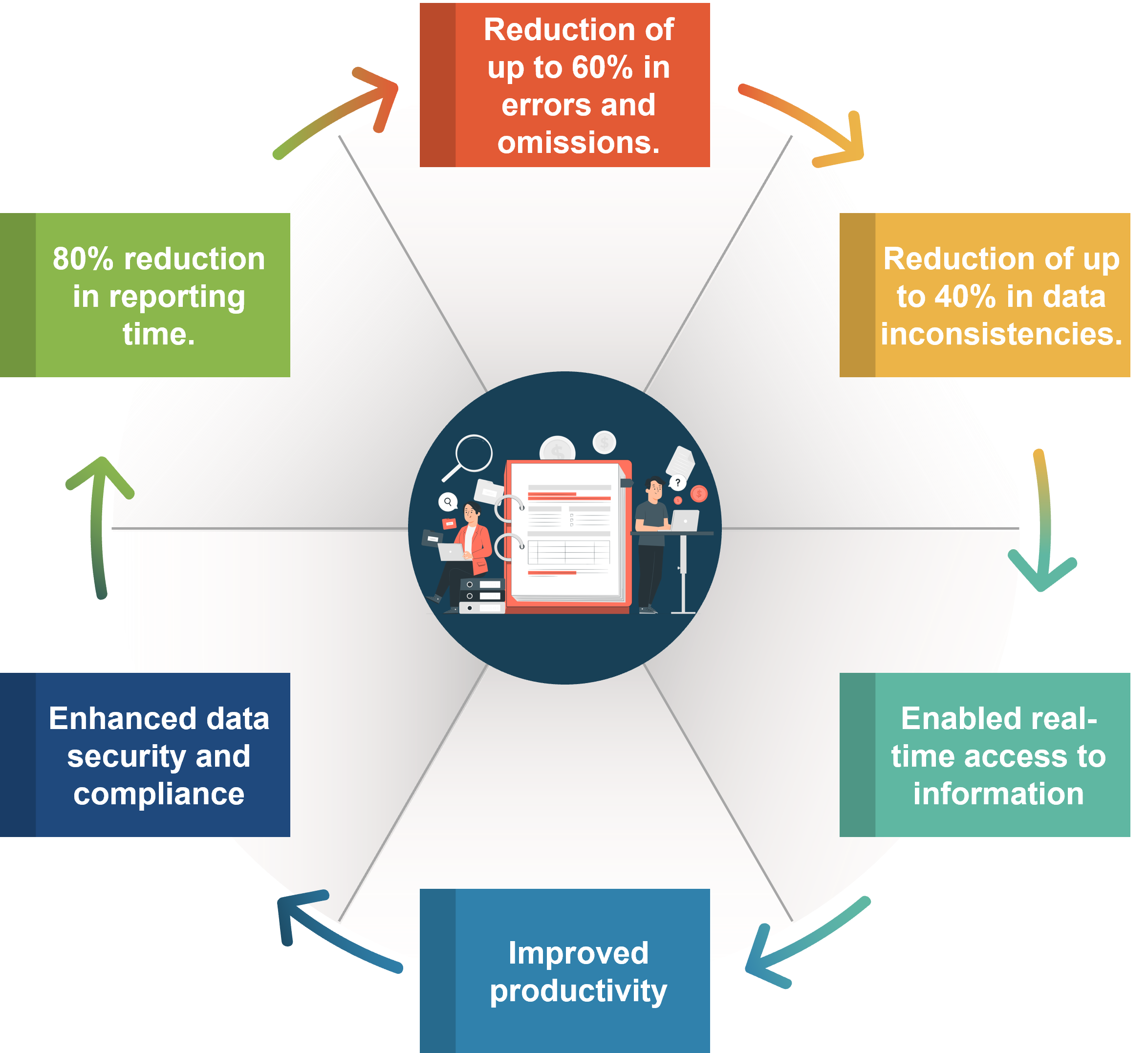
The following are the quantified outcomes for the case study of implementing big data analytics for capital analysis for a major financial services company:
Reduced capital reporting cycle time from days to hours, resulting in an 80% reduction in reporting time.
Improved accuracy of regulatory reporting with a reduction of up to 60% in errors and omissions.
Improved data quality with a reduction of up to 40% in data inconsistencies.
Reduced risk by enhancing data accuracy, timeliness, and completeness.
Enabled real-time access to information for decision-making, improving the ability to make informed business decisions.
Improved productivity by providing an automated, standardized, and streamlined process for data collection, processing, and analysis.
Enhanced data security and compliance by ensuring that sensitive data is protected and meets regulatory requirements.
Overall, the implementation of big data analytics for capital analysis provided the financial services company with significant benefits, including improved efficiency, accuracy, and risk management. It also enabled the company to make informed business decisions based on real-time data, improving its overall performance and competitiveness.
Latest Case Studies
Our Case Studies
 & Conversational AI - Banner.jpg)



.jpg)

.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)

.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)



.jpg)


.png)
.png)
.jpg)

.jpg)
.png)
.png)
.png)

.png)
.png)
.png)



.jpg)

.jpg)


.jpg)



.jpg)


.jpg)